Scaling Engineering: Generalism to Specialism
December 20, 2022.
The traits that make someone successful at one stage of a company or team, aren't necessarily those that make them successful at a later stage. You've probably heard something like this before, it's become a truism when scaling technology companies; so much so that venture capitalists often refer to it as the Schmidt Point.
This idea is frequently applied to an organisations senior management, where one individual's impact (or lack thereof) is more acutely felt, "Sorry Bob, you were a great CEO when the company was 50 people, but you're struggling now it's 500". This transitional idea was one of the strongest messages that came out of the 400+ interviews and survey responses for my book.
Optimising for hyphens
In the early stages of a startup or at the inception of a new team, generalism is impactful. People who can take on a variety of subjects or tasks enable a small group of people to tackle problems quickly and effectively. Ownership can be taken end-to-end, dependencies and handovers minimalised. All the things that can cause large teams to struggle can be eliminated through people with broad skills and an entrepreneurial attitude. These are less T shaped people than - shaped people.
For example, a full-stack engineer who can turn her hand to design, front-end engineering, back-end engineering or operations is a profile that early-stage teams highly value; but as the inherent complexity of the thing that teams works on increases this "generalism" becomes less impactful. When she's initially asked to do five end-to-end "new things" for the product she's building she can manage, but when the complexity increases of what she's working on and she's asked to do thirteen "new things", the complexity she asked to manage becomes more difficult:
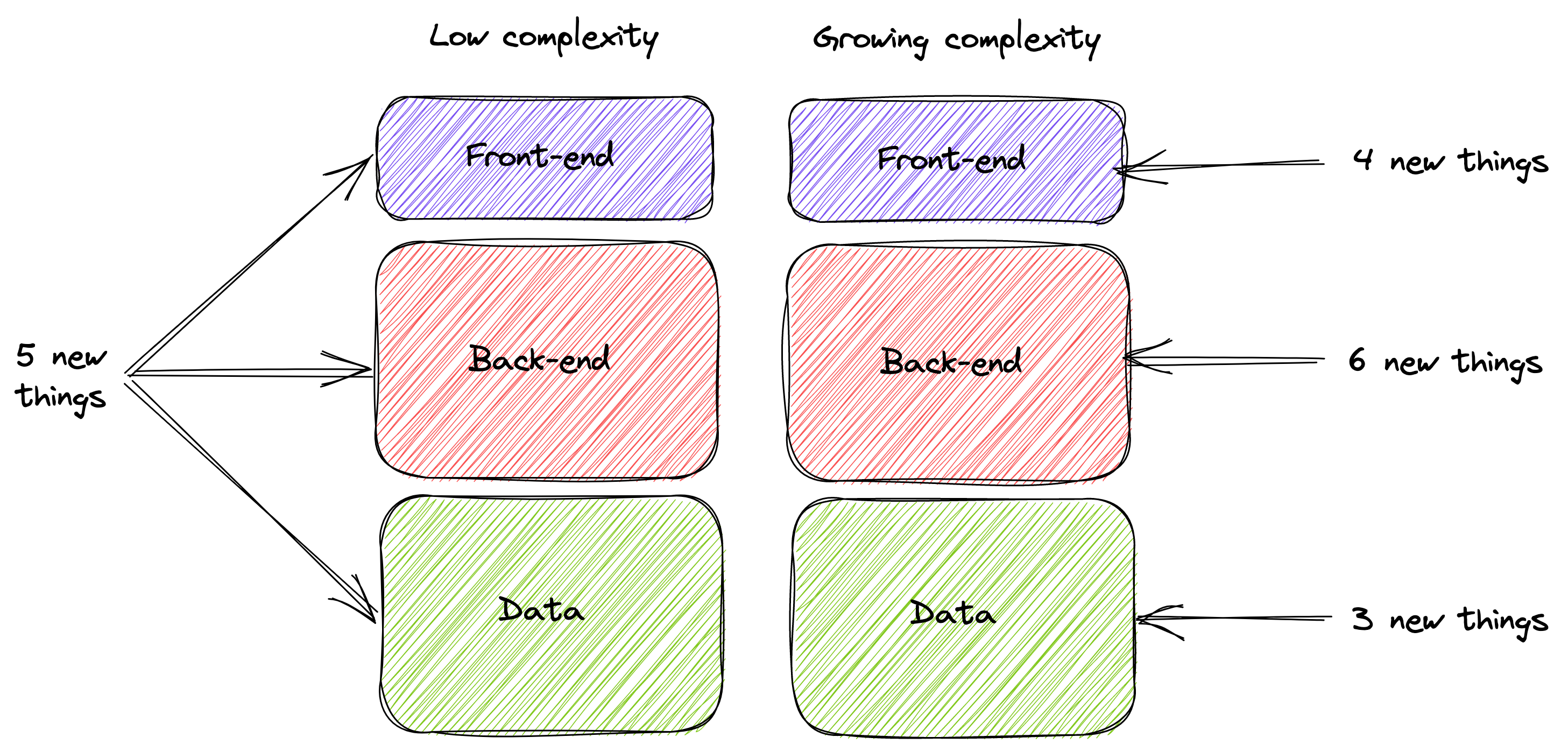
Descending the "T"
Intuitively, we understand that complexity tends to grow with scale. For engineering teams, this complexity growth can be technological, operational or any of a dozen other vectors. As this complexity grows, it becomes increasingly difficult for single humans to hold of it in their brain, let alone be effective working within it.
There are of course exceptions to this (individuals who hold and operate with that much complexity) but our respondents tell us clearly: this isn't something you can scale. You may find one of these people, but what happens when you need to hire ten of them?
Due to this increasing complexity, most engineering organisations naturally evolve to different people working on different parts of the previous problem. Broadly, this ends up looking like one of two approaches:
- Break issues up into "vertical" slices. Keeping the end-to-end nature of ownership in an individual or small number of people, but reduce the complexity. For example, instead of one engineer delivering a whole product end-to-end, it may be broken up into "vertical" units and split it between several engineers.
- Break issues up into "horizontal" slices. Breaking up the end-to-end ownership into layers within the product. For example, instead of one engineer delivering a complete product end-to-end, one engineer would deliver a front-end, one delivers an API etc.
There is no one perfect answer to which is the right option, and in fact, our respondents said they got it wrong repeatedly. Which to a valuable conclusion, that optimising for the fact it will change, and you will get it wrong as you scale is more important than getting it right the first time.
The impact on attrition
This change in individuals remit and responsibility was identified as the second-largest reason for attrition in engineering teams as they grow (the number one, if you're curious, was not growing compensation in line with company growth).
This contribution to attrition was particularly acute when engineering teams grew from 25 to 100 people. During this period, 68% of our respondents identified it as the top cause of attrition.
In our survey, we referred to attrition in two ways: as "regrettable attrition" (in other words, the employees that an organization would have liked to keep but who decided to leave); and "non-regrettable attrition" (in other words, the employees who left the organisation for other reasons. It could be, for example because their contract ended or because it was terminated). These terms are a bit opaque to most people, but are commonly used in people and talent teams.
One of the most interesting facets of this attrition data is that of the people who left for the "reduced influence" and "reduced domain size" reasons, only a small percentage of them (18.2%) were thought of as "regrettable attrition". In other words, engineering leaders thought that it was appropriate that these people left their organisations when they did, and they broadly did it for the right reasons.
Optimising for specialists
As complexity grows, specialism becomes the norm in engineering teams. This specialism can be "functionally" focused, for example, having the in-depth domain knowledge of a small part of a larger product, or it can be "non-functional" for example, by focusing on a particular part of the software stack.
This transition can be hard to make for leaders, and many reflect that they didn't get the timing or balance right as they scaled their teams. In the next extract from Scaling Engineering, we'll cover some important timing lessons from our respondents.